Das zentrale Datenhub des VDMA Verlags - Das Tango REST Interface
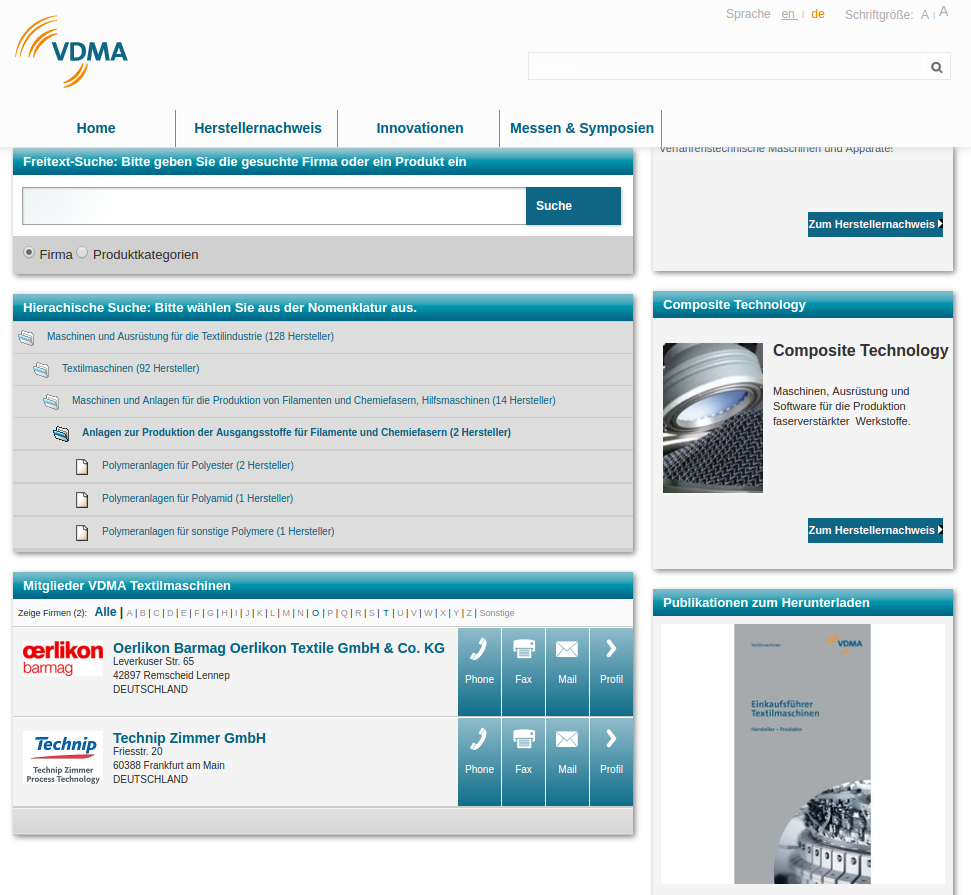
Wie bereits im Blog-Post „Mehrwert für VDMA Mitglieder im Zeitalter von Industrie 4.0“ erwähnt, gibt es für einige Fachverbände spezifische Websites. Diese beinhalten neben den Informationen zu den Mitgliedsfirmen oder der Nomenklatur weiterführende Informationen, z. B. über Messen, Neuigkeiten und andere relevante Themen. Um jede Seite mit den spezifischen Informationen aus dem Tango Backend versorgen zu können, wurde eine Schnittstelle entwickelt, das sogenannte Tango REST Interface, kurz TRI. Eigentlich handelt es sich dabei nicht um ein REST Interface, da nur Daten via GET abgerufen werden können. Mithilfe dieser Schnittstelle können nun die Inhalte aus dem Tango Backend entweder fachverbandsübergreifend oder für einen spezifischen Fachverband abgerufen werden. Mittels verschiedener Parameter kann die Abfrage gesteuert und auch gefiltert werden, wie z. B. anhand der Sprache, der Kategorie in der Nomenklatur oder anderer Angaben. Auch eine Volltextsuche ist möglich: Der oder die Suchbegriffe müssen lediglich als entsprechender Parameter bei der Abfrage mit übergeben werden.
Die Schnittstelle bietet folgende Funktionen:
- Abfrage von Inhalten
- Fachverbände
- Firma/Firmen
- Fachverbands-Nomenklatur oder einzelne Kategorie(n)
- Länder
- Repräsentanten
- Anwenderberichte
- Innovationsberichte
- News
- Umkreissuche von Firmen
- Filter
- Fachverband/Fachverbänden
- Firma/Firmen
- Anfangsbuchstaben von Firmen
- Kategorie(n)
- Ebenen in der Nomenklatur
- Sprache
- Startposition
-
Anzahl der Inhalte, die übergeben werden sollen
Für alle Abfragen existiert jeweils eine Singular- und eine Pluralmethode, mit denen es möglich ist entweder viele Inhalte eines Typs oder nur einen bestimmten Inhalt abzurufen, um z. B. die Detailansicht einer Firma darzustellen. Damit Unbefugte nicht auf die Daten aus dem Tango Backend zugreifen können, wurde ein Sicherheitskonzept eingebaut.
Die technische Umsetzung dieser Schnittstelle ist eine Kombination aus dem CMS Drupal und Apache Solr. Die Inhalte werden in Apache Solr indiziert. Hierbei werden auch teilweise die Antworten generiert und im Index direkt mit abgelegt. Auf diese Weise müssen keine Datenbankabfragen gestellt werden, was die Antwortzeiten signifikant verkürzt. Apache Solr liefert die Möglichkeit, viele Daten sehr schnell zu suchen, zu filtern und auszuliefern, sodass eine Webseite schnell eine Antwort mit den gewünschten Daten erhält, diese verarbeiten und ausgeben kann. Die Auslieferzeiten dieser Schnittstelle liegen im Durschnitt zwischen 100 und 300 ms, sodass ein Seitenaufbau auf der Webseite innerhalb einer Sekunde erfolgen kann.

Unser Experte

Carsten Müller
Carsten Müller arbeitet seit 2005 bei Cocomore. Als Senior Manager Software Developer konzipiert und erstellt er komplexe und umfangreiche Websites (und repariert keine Computer ;)). Zuvor war er bei SevenOne Intermedia, einer Tochter der ProSiebenSat1 Gruppe, tätig.
Carsten in drei Worten beschrieben: Nordisch by nature.
Haben Sie Fragen oder Input? Kontaktieren Sie unsere Expert:innen!




